
The CERL annual seminar on collaborative digital methods
The Consortium of European Research Libraries recently held its annual seminar for 2019 in the Historisches Gebäude of the Staats- und Universitätsbibliothek, Göttingen under the title of “Collections and Networks: Reconstructing the historical context of texts, publications and objects with digital methods.” CERL was founded in 1992 with an explicit mission to provide collaborative information resources and networks for sharing expertise, and includes nearly 300 libraries as members. This membership now extends to the Americas, with major research libraries outside Europe also contributing to and benefiting from CERL’s work. CERL provides access to collaborative databases such as the Heritage of the Printed Book , Material Evidence in Incunabula, and the CERL Thesaurus of place, personal and corporate names of the handpress period, all of which are freely accessible to scholars, and to which member libraries are invited to contribute their collection data.
The conference began with an introduction by Kristian Jensen, Chairman of CERL, and Wolframm Horstmann of SUB Göttingen, discussing the importance of the organisation in facilitating access to research data for as many people as possible. The strength of the CERL network lies in the two-way relationship between its members as both suppliers of the core data its resources bring together, and as beneficiaries of these collaborative databases for scholarship. With this core message in mind, the speakers fell into two groups; those who were using extant datasets in new ways, and those using new technologies to create data from material that had previously not been machine readable
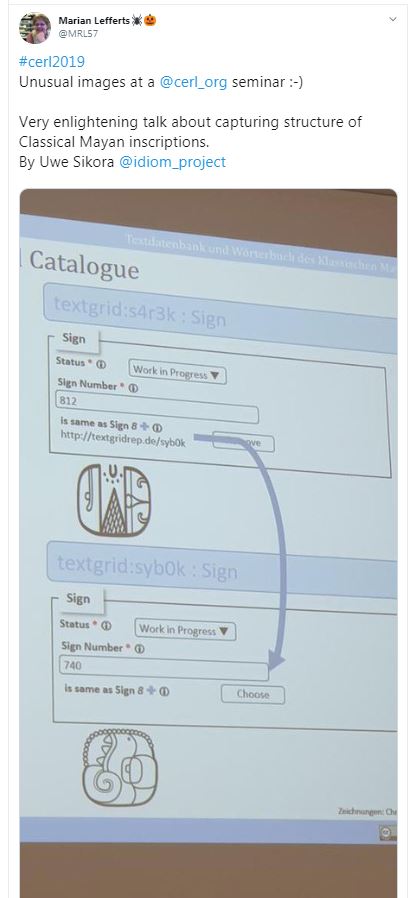
Uwe Sikora of Göttingen spoke on the use of TEI and XML markup to record texts in the Mayan language, as part of a 15-year project to create the first dictionary of the language. This is an immensely complex undertaking as there are multiple layers of evidence for each source: the location of the text on the carrier; the signs which are written (which can bear multiple meanings); and the liguistic interpretation of these signs into words. There are around 1000 signs, which can be presented in some 3000 variant forms. CERL Executive Manager Marian Lefferts tweeted an image showing two letter forms which are palaeographical variants of one another, putting the struggles faced by readers of early modern English handwriting into perspective. These symbols can be recorded on many different carriers, and this also has a bearing on the meaning of the written text.
The importance of the recording of evidence from different types of material was also core to the paper presented by Susannah Al-Eriyani. She worked on a project to use metadata to bring together the digital records of several thousand items (books, manuscripts and artefacts) given in the eighteenth century to Göttingen by Baron von Asch and now dispersed, because of their wide ranging subjects and formats, among seven different university collections. Her work began with research among users and holders of heritage collections, to establish what types of data users of those collections actually wanted, and then provided a model to bring this information together using RDF relationship statements. Research with end users was also an early stage of the work done by Andreas Walker on using a linked data approach to the Heritage of the Printed Book database to meet the needs of current users. He interviewed academics who already use the HPB to understand what they want from it in the future and created a revised version of the database in which they could build their own advanced enquiries rather than being limited by set search options. A strong message behind his work was that users may be domain experts – they know a lot about book history and the content of the database – but are not tech experts, and should not be expected to learn new skills in order to get the best from the database. This was a very popular opinion with those of us in the audience from a less technical background.
Brian Geiger and Bryan Tarpley discussed the ongoing project to create a more interactive version of the English Short-Title Catalogue (ESTC) identified as ESTC21. This would invite users to submit their own information about potential new editions or corrections to extant records, with an editorial board to approve these suggested amendments to the database. They acknowledged that the current database includes many placeholder and unedited records, and the new version would enable crowdsourced updates from scholars working on the material, as well as linking to digitised copies in open access databases such as google books. There is also the potential for holding libraries to have accounts which could trace comments made on their own holdings. With some 90,000 copies listed in the ESTC, this would be fascinating for the UL.
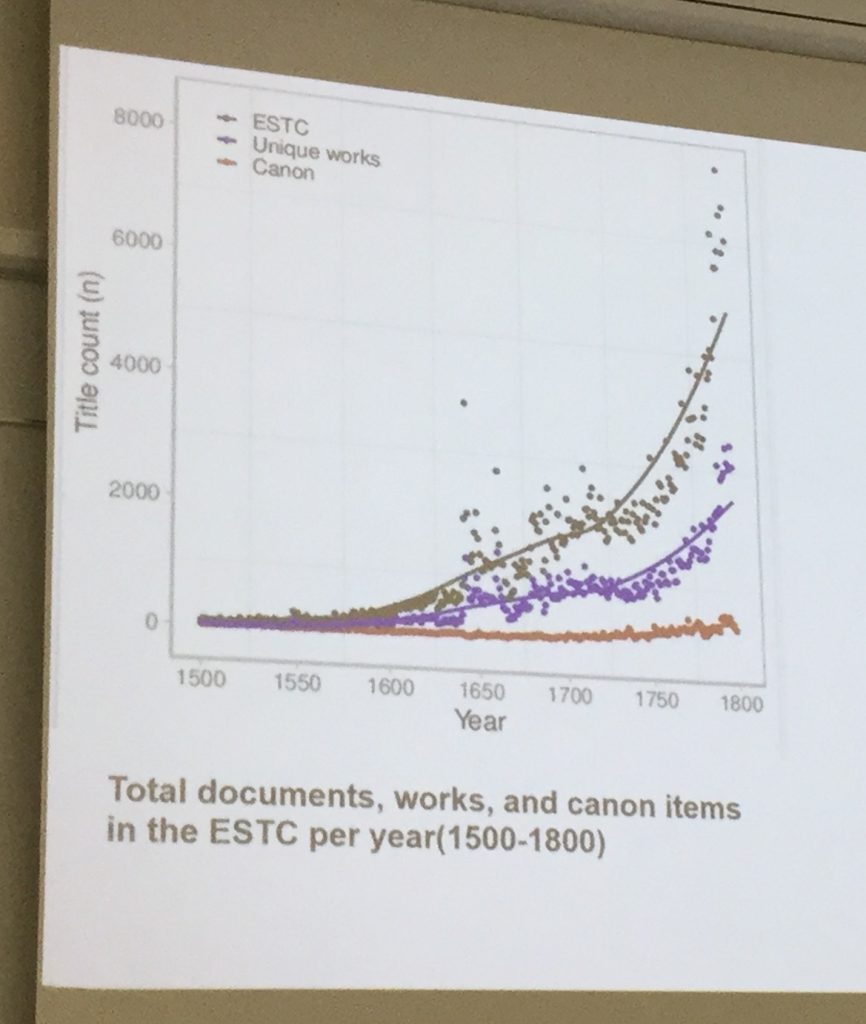
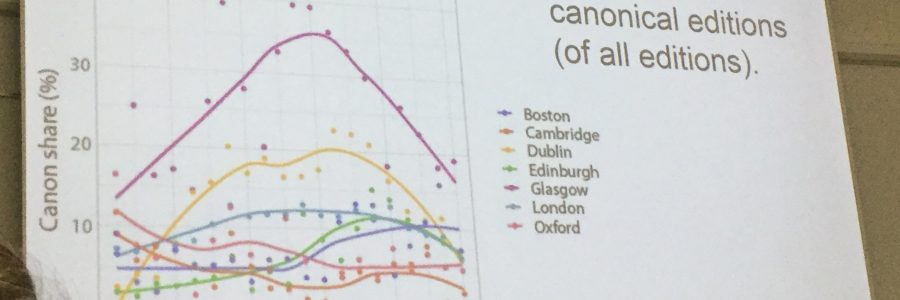
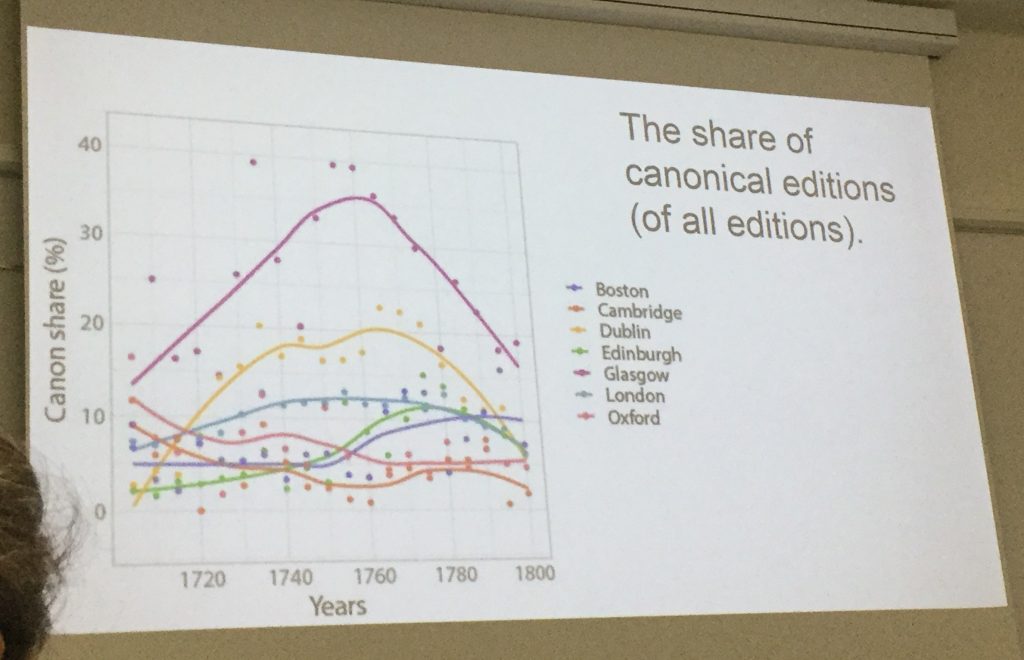
A brilliant demonstration of how to analyse data on a large scale was presented by Miko Tolonen and Leo Lahti. Their explicit aim was to take a new approach to the data in ESTC and the HPB, avoiding a nationally delineated perspective and working with historians and data scientists to avoid bias in their analysis. One section looking at the reprinting of 800 canonical works (those printed most frequently) produced striking visualisations in which clear patterns could be determined. This enabled them to spot easily that, for instance, the publishing houses of Dublin and Glasgow were reading their markets, and a large proportion of their work was reprinting of canonical works with a guaranteed buying audience.
Other papers covered the Reassembling the Republic of Letters project; the British Library’s Living with Machines project; Semantic networks in structured text data based on Theodor Fontane’s Notizbücher; the creation of a new manuscript database to replace Manuscripta medievalia, incorporating a IIIF interface; and the creation of a Specialised Information Service resource on book history and Library and information science. Many of the presentations are available on the conference web pages.